The AWK Programming Language: An Introduction
A hands-on tutorial for learning AWK on Linux
Introduction
The AWK utility is known for running programs that perform text processing and data extraction, and is often pre-installed on Linux and UNIX based operating systems. This article adopts a hands-on approach to introduce the AWK programming language. Many sample programs are provided as new AWK concepts are discussed throughout. After completing this article, you will have a good understanding of how to write AWK programs to process, extract and report data on your system.
A Brief History and Installation
The first version of the AWK language was created at Bell Labs in 1977. The “AWK” acronym is derived from the surnames of its creators — Alfred Aho, Peter Weinberger, and Brian Kernighan — and shares the same pronunciation as the auk bird. The lowercase version, “awk”, refers to the program that runs scripts written in the AWK programming language. This type of program is known as an interpreter.
Since its initial release, AWK has been forked and developed further by multiple groups of people. As a result, several versions of AWK exist today each with varying implementations. The programs presented in this article are written for the GNU Awk implementation, also known as Gawk.
Gawk is installed via the gawk package using your distribution’s package manager. It will probably be installed on your Linux distribution already and linked to the awk command. In other words, the awk and gawk commands will invoke the same program.
Use your distribution‘s package manager to install Gawk if it’s not already on your system:
$ sudo pacman -S gawk # Arch
$ sudo apt install gawk # Debian and Ubuntu
$ sudo dnf install gawk # Fedora and CentOSWe can also confirm the install location and the fact awk is a symbolic link that points to the gawk binary:
# Output gawk location
$ which gawk
-| /usr/bin/gawk# Output awk symbolic link location
$ which awk
-| /usr/bin/awk# Confirm awk is a symbolic link
$ ls -l $(which awk)
-| lrwxrwxrwx 1 root root 4 Apr 15 2020 /usr/bin/awk -> gawk
Lastly, run awk with some basic command-line options to get acquainted with the tool:
# Output version (--version)
$ awk -V
-| GNU Awk 5.1.0 ...# Output license (--copyright)
$ awk -C
-| Copyright (C) 1989, 1991-2020 Free Software Foundation. ...# Output usage (--help)
$ awk -h
-| Usage: gawk [POSIX or GNU style options] -f progfile ...
Now you have Gawk installed, let’s proceed to the next section which discusses how to run AWK programs!
Running AWK Programs
An AWK program is data-driven, which means that it performs a set of actions on the textual data it receives. There are two methods for supplying data to a program: Specifying a list of filenames, and piping output from another command. These approaches can be observed with some pseudo code:
# Providing input files
awk 'program' input-file1 input-file2# Piping the output of a command
command | awk 'program'
In addition, the program portion can be either:
- A one-shot throw away program that is quick to type and specified on the command line.
- A script defining a sophisticated program that performs more complex data processing.
The best approach to take will depend on your program’s overall complexity and whether you want to re-use it in the future. The following pseudo code illustrates how to provide an AWK program:
# Command line
awk 'program' input-file1 input-file2 ...# Program file
awk -f program-file input-file1 input-file2 ...
Notice that a program specified directly on the command line is surrounded in single quotes. Alternatively, you can provide a program file with the -f flag.
It is also a good idea to append the .awk file extension to your scripts for a couple of reasons. It enables editors to render syntax highlighting for the AWK programming language correctly, and it immediately conveys the nature of the file when it's listed in a file manager or terminal.
Running Throw-Away Programs
Here are some quick one-shot example programs invoked directly on the command line. Feel free to run each one in your terminal, and don’t worry if the syntax makes no sense at this point:
# Output total number of fonts in /usr/share/fonts
$ fc-list | awk 'END { print "Total fonts:", NR }'# Output all (hidden) files starting with ".bash"
$ ls -la | awk '$NF ~ /^.bash/ { print $NF }'# Output all filenames that contain more than 10 characters
# (minus file extension)
$ ls | awk '{ i=index($0,"."); i>0?s=substr($0,1,i-1):s=$0;
if(length(s)>10) print }'
Throw-away programs can also process text files:
# Create a text file listing system fonts
$ fc-list > font-list# Provide the text file and output total number of fonts
$ awk 'END { print "Total fonts:", NR}' font-list
Programs specified on the command line can be more than one line, but you will need to use the backslash character to separate each one:
$ ls -l | awk 'BEGIN { print "About to count files..." } \
{ ++count } \
END { print "Total files: ", count }'These types of programs are great for getting information quickly and experimentation. However, writing programs in text files means there is no limit to the complexity or length of your program.
Running AWK Scripts
We will use a script provided in this article’s corresponding GitHub repository to discuss the concepts in this section. You can download the GitHub repository containing this article’s code examples using git on the command line:
$ git clone https://github.com/danebulat/awk-samples.gitThe program discussed in this section is located at samples/filemod.awk. The script renames files in the current working directory by converting all the characters to either lowercase or uppercase. When no command-line options are specified, all filenames are converted to lowercase:
# Enter samples directory
$ cd awk-samples/samples# Add executable permissions to the scripts
$ chmod +x *.awk# Invoke script
$ ls -la | ./filemod.awk
After piping ls -la to ./filemode.awk you should see some formatted output informing you of any modifications to the filenames:
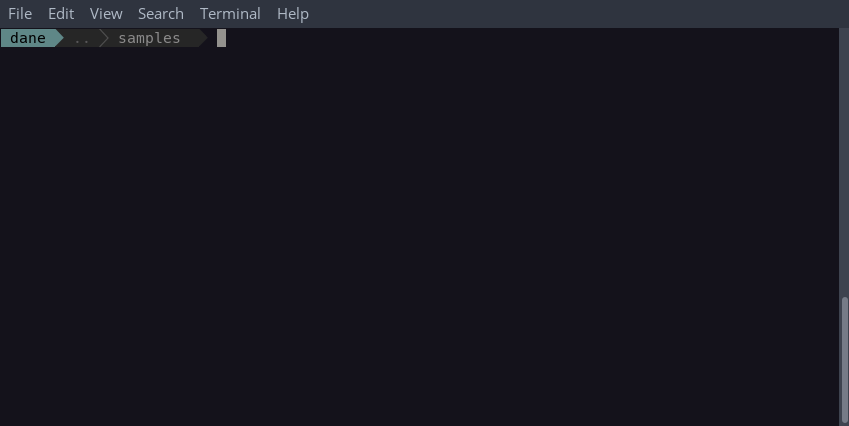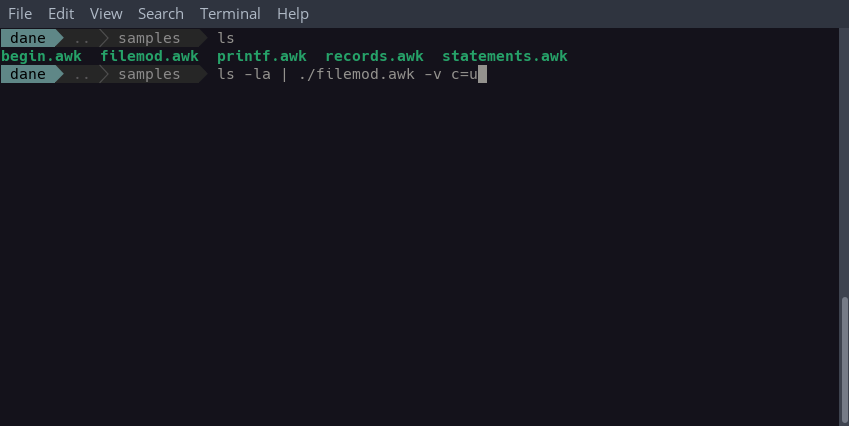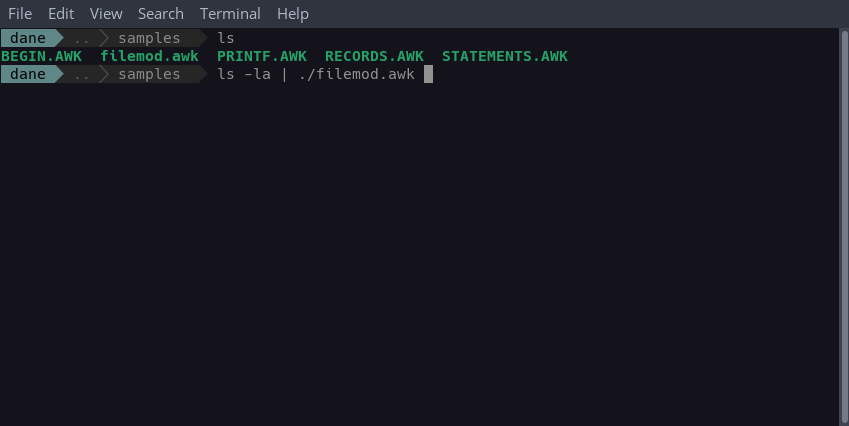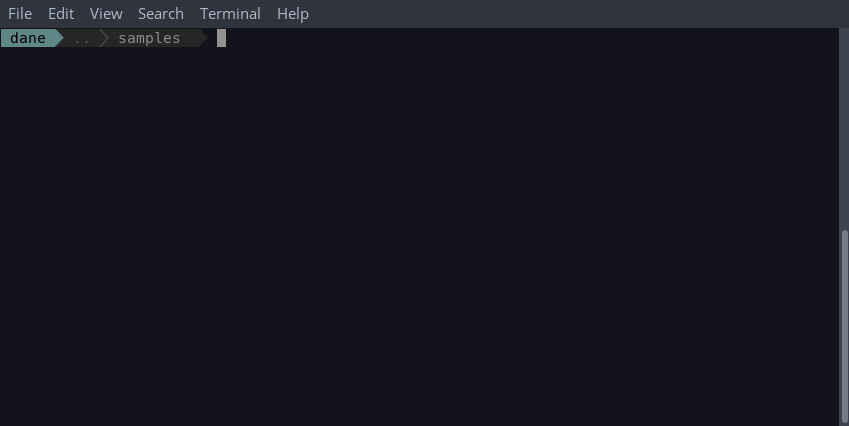
Let’s discuss the commands that were necessary to run the script:
chmod +x *.awkIn order to use the./program.awkshorthand syntax, the scripts must have executable permissions.ls -la | ./filemod.awkThe program receives output fromls -laand disregards lines representing hidden files because dotfiles should not be renamed. The initialtotalline is also skipped.
If you want to invoke programs using the ./program.awk syntax, a shebang character sequence must also be specified at the top of a script pointing to your AWK binary, followed by the -f flag:
#! /usr/bin/awk -fAlternatively, the longer invocation method is to specify the awk utility and pass a script’s filename to the -f flag explicitly:
$ ls -la | awk -f filemod.awkRunning a script this way doesn’t require it to have executable permissions, nor does the shebang character sequence have to be specified at the top of the file. However, I would recommend using the shorthand syntax because less typing is required.
Our program also accepts a variable assignment on the command line which instructs it to perform either lowercase or uppercase conversion:
$ ls -la | ./filemod.awk -v c=l # lowercase conversion
$ ls -la | ./filemod.awk -v c=u # uppercase conversionVariables passed to a program from the command line must appear after the -v option. If a value other than l or u is assigned to the c variable, or we don't assign any variables, the program converts to lowercase by default.
Patterns and Actions
An AWK program is made up of rules, and rules are made up of a pattern with associated actions. You therefore build an AWK program by defining a list of rules that have the following structure:
# AWK program
pattern { actions } # Rule
pattern { actions } # RuleEach rule can specify one pattern in addition to a set of actions. The following subsections will discuss this workflow in more detail.
Patterns
A rule doesn’t have to include any actions if a pattern is defined. Likewise, it doesn’t need to define a pattern if an action is defined. However, one of them is needed for the program to do some processing on the data it receives.
A pattern is specified before the action code, and can be either a conditional expression or regular expression:
# Regular expression examples
$ ls -l | awk '/(\.py)&/'
$ ls -l | awk '/README/'# Conditional expression examples
$ ls -l | awk '$NF == "README.md"'
$ ls -la | awk '$NF ~ /^\./ { printf $NF }'
Let’s take a look at each pattern in the examples above:
/(\.awk)$/
Forward slashes are used to denote regular expressions in AWK. Within them, you can input standard regular expression characters to define your pattern. In this example, all files with the.awkextension are matched./README/
No special characters are used within this pattern, which means if an input record contains the textREADME, it will be matched and the corresponding action block will execute if one is defined.$NF == "README.md"A pattern can also be a conditional expression using the same operators found in C and C++. For example, this pattern checks the value inside the predefined AWK variable$NF, which references the last field in the current input record. If$NFcontains the stringREADME.md, the pattern matches and the associated action block is executed.$NF ~ /^\./
The regular expression/^\./matches on strings that begin with a period character, representing a hidden file. The~operator performs a comparison on the string inside the$NFvariable with the regular expression. Note that the!~operator is also available.
A pattern needs to return “true” in order for the action block to run. AWK understands truthness in the following way:
- True is defined as any nonzero numeric value, or any nonempty string.
I.e."Hello, world!",10,“Three”,"0"are all true. - False is defined as zero or the null string.
I.e.""and0are false.
With the understanding that a rule is executed when its pattern matches the current input record, let’s proceed to discussing actions next.
Actions
AWK will always run the action block if a pattern is not provided. If a pattern is provided, it needs to return a true value in order for the action block to run.
An action is always defined inside curly braces {...} and consists of one or more statements. Either a semi-colon (;) or a newline separate statements in AWK. A one-shot program will use semi-colons to separate statements:
$ ls -l | awk '{ print "Filename:", $NF; print "\tOwner:", \
($3 == "" ? "--" : $3) }'However, a script will likely separate statements on separate lines to properly format the code, making it more readable:
In the script above, the print function is called to format and send data to the standard output. This program is saved as samples/statements.awk in the source files and can be invoked on the command-line:
$ ls -l | ./statements.awkIn the event that an action is not specified for a rule, the whole input record is sent to standard output where the following action code is run implicitly:
{ print $0 }The $0 here is another predefined variable which stores the string of the current input record. If you are wondering why you are seeing output after not defining any actions in your AWK programs, this is what's going on behind the scenes.
Regarding the sample/filemod.awk program, three rules are defined where two of them use special patterns:
BEGIN { ... }This rule uses the specialBEGINpattern. It causes the rule to execute exactly once when the program starts, before the first input record is read.$NF !~ /^\./ && $1 !~ /^(total)/ { ... }This rule processes the input record providing it doesn't represent a hidden file or begins with the stringtotal. Two regular expression comparisons are performed with the!~operator to accomplish this.END { ... }This rule uses the specialENDpattern. It causes the rule to execute exactly once after all input is read and before AWK exists.
Let’s take a closer look at the BEGIN and END patterns in the next section.
BEGIN and END Patterns
The BEGIN and END patterns are useful for providing startup and cleanup actions for your program. For example, a BEGIN block could print headings if a program renders table data, and an END block could output summary information. The samples/begin.awk program demonstrates the BEGIN and END patterns:
This script renders Filename and Permission column headings inside the rule containing the BEGIN pattern. Notice that the printf function is used for making the first column a minimum of twenty characters wide.
Additionally, the rule containing the END pattern outputs the value of the $NR predefined variable, which stores the number of input records that have been processed so far. Feel free to run the script in the following way and observe its output:
$ ls -l | ./begin.awkInput Records and Fields
Records
AWK processes data in units called records. Each record is separated by the newline character (\n) — meaning a record is one line of input by default. Additionally, AWK stores the current input record in a predefined variable called $0, which can be referenced in your programs:
# Output input records
$ ls -l | awk '{ print "Current record:" $0 }'# Same behavior with text files
$ ls -l > file-list
$ awk '{ print "Current record:", $0 }' file-list
The character used for separating records is stored in a predefined variable called the record separator denoted by RS in your programs. This variable can be modified in situations where input needs to be separated differently:
# Treat each directory as an input record
$ pwd | awk 'BEGIN { RS="/" } { print "-->", $0 }'Notice that the record separator character is not actually included in the input record. Another three useful predefined variables are available in regards to record processing:
FILENAME
Contains the name of the current input file.FNR(File Number of Records)
How many records have been read from the current input file.NR: (Number of Records)
How many records have been read in total.
The samples/records.awk program uses these variables to output the first ten records within the text files passed to the program:
The program checks if FNR contains the value 10 after outputting the current record. If it does, a message is displayed and the nextfile function is called to process the next input file. To invoke the program, simply pass some input files on your system such as /etc/passwd and /etc/group:
$ ./records.awk /etc/passwd /etc/group
-| Outputs first 10 records in /etc/passwd and /etc/groupFields
Each record is automatically split into chunks called fields. Similar to records, fields are separated by the value of a predefined variable called the field separator denoted in your programs with FS.
The default value of FS is a space character, which carries the meaning that fields are separated by runs of white space - such as leading and trailing space and TAB characters.
Field separation can be observed by outputting the value of the NF, which is a predefined variable that stores the number of fields each record contains:
$ ls -l | awk '{ print "Number of fields in record:", NF }'
-| Number of fields in record: 2
Number of fields in record: 9
...Individual fields can also be accessed with special variables in the form of $N where N is the field index. The first field in a record has an index of one, and is therefore accessed with $1. The second field is referenced with $2, and so on. The last field can also be accessed with the $NF variable, which is useful if you don't know the actual index value. Let's take a look at an example:
# Output filenames and modification dates
$ ls -l | awk '{ if (NR>1) print $NF, "\tmodified on", $6, $7 }'The field separator will sometimes need modifying if data received by the program is formatted differently. For example, fields inside the /etc/passwd and /etc/group configuration files are separated with the colon (:) character. To access these fields correctly within an AWK program, the field separator needs to be set accordingly:
# Output system users and their home directory
$ awk 'BEGIN { FS=":" } { printf "%-30s%s\n", $1, $6 }' /etc/passwdThe printf function is used again here to format columns appropriately. As well as within the BEGIN block, FS can also be set on the command line through the -F option:
$ awk -F: '{ printf "%-30s%s\n", $1, $6 }' /etc/passwdAs with the record separator, It is possible to assign a regular expression to the field separator where fields are separated by occurrences of characters that match the regular expression. This is an advanced feature but mentioned here for completeness.
Record and Field Splitting Summary
The following two tables summarize the behavior of the RS (Record Separator) and FS (Field Separator) variables depending on their assigned value. Feel free to refer to them if you need a refresher.
Printing Output
One of the strengths of the AWK programming language is its ability to efficiently format data and produce meaningful reports. This functionality is provided by the print() and printf() functions in combination with a few predefined variables.
The print Function
The print() function is used to output text with simple, standardized formatting. You will probably use this function if you just want to output some variables and strings in a linear way. The syntax is also very simple:
# Items separated with commas
print item1, item2, ...
print(item1, item2, ...)# Items separated without commas
print item1 item2 item3
print(item1 item2 item3)
The syntax presented above illustrates a couple of important points:
- You can provide optional parenthesis when calling
print. Parenthesis are only required if redirection is performed with the>operator. - Items can be separated with or without a comma character.
While separating items with and without a comma are both syntactically correct, AWK will process your arguments differently depending on which method you choose. let’s take a look at an example:
# With commas
$ awk 'BEGIN { print "Hello", "World" }'
-| Hello World# Without commas
$ awk 'BEGIN { print "Hello" "World" }'
-| HelloWorld
From the output of these commands we can deduce that items are separated with a space character if a comma is used, and simply concatenated if a comma is not used.
As a matter of fact, you don’t even need to separate items if you just want to concatenate them:
$ awk 'BEGIN { print "Hello""World" }'Although this works, I would recommend separating items with a space to make your code more readable!
The fact that a space is output between items when a comma is specified in print is no coincidence. The space character is actually the default value of a predefined variable called the output field separator denoted by OFS in your programs. This variable can be set to any string if you require something other than a space to separate your items:
# Setting the output field separator
$ awk 'BEGIN { OFS=" ---> "; print "Hello", "AWK", "World"}'
-| Hello ---> AWK ---> WorldAWK also provides a predefined variable called the output record string which is denoted by ORS in your programs. The string stored in this variable is a newline character by default (\n) and is output before the print function exits. The ORS variable can be set to any string if you require something other than a newline character to separate print output:
# The default ORS is a newline character
$ awk 'BEGIN { print "Hello"; print "World" }'
|- Hello
World# Setting ORS to a new string
$ awk 'BEGIN {ORS=" [END OF RECORD]\n";print "Hello";print "World"}'
|- Hello [END OF RECORD]
World [END OF RECORD]
The last predefined variable we will look at in this section is called the output format and is denoted by OFMT in your programs. It stores a string representing a format specifier that controls how numeric output is displayed with the print function. The default value is %.6g:
%g: Prints a number in either scientific notation or in floating-point notation - which ever uses the fewest characters..6: A period followed by an integer representing the precision. Signifies the maximum amount of significant digits when used with%gformat specifier.
The OFMT variable can be modified just like ORS and OFS:
# Default OFMT is "%.6g"
$ awk 'BEGIN { print 3.141592653, 6.283185306, 12.566370612 }'
-| 3.14159 6.28319 12.5664# Setting OFMT to a new format
$ awk 'BEGIN { OFMT="%6.3f"; print 3.141592653, 6.283185306, 12.566370612 }'
-| 3.142 6.283 12.566
We set the output format to %4.3f which specifies that:
- A minimum of four digits are output for every number.
- A maximum of three digits are output after a decimal point.
The recommended practice is to set OFS, ORS and OFMT in the BEGIN block before your input records start processing.
The printf Function
The printf function is a powerful tool that enables you to format output to match your exact requirements. For example, it is straight forward to output columns of certain widths, as well as formatting a number’s precision.
The syntax of printf is similar to print, except the first argument is always a format string:
printf format, item1, item2, ...
printf(format, item1, item2, ...)The format string is a specification of what is to be output by printf. Within it you include format specifiers as well as regular text. The subsequent items after the format string are what will be plugged into the format specifiers.
Let’s take a look at the samples/prinft.awk example program in the GitHub repository:
This program is responsible for displaying a list of files and their permissions in a readable way. Invoke it on the command-line by piping the output of an ls -l command:
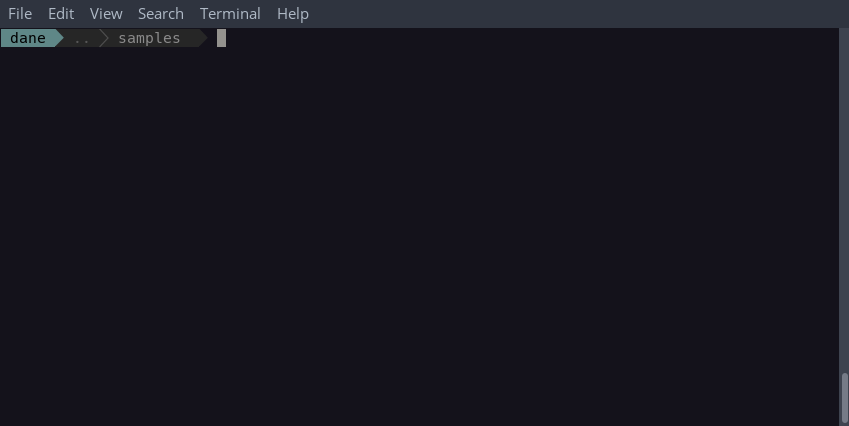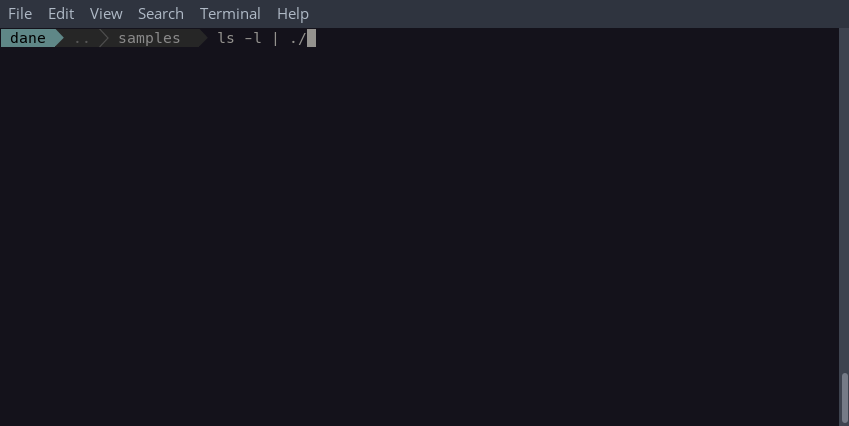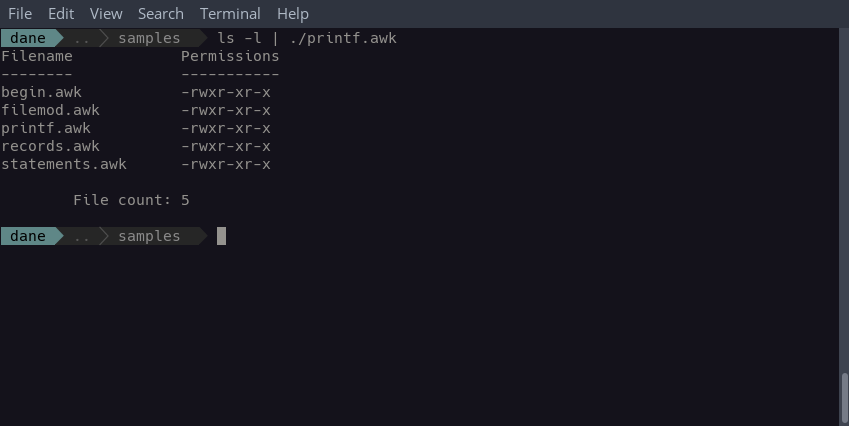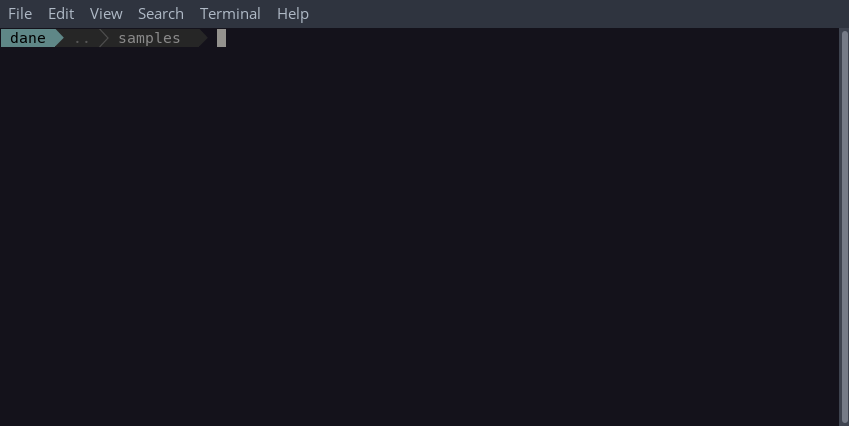
The printf function is used to format the output in this program.
format = "%20-s%s\n"A variable calledformatcaches a format string so we can pass it to multiple invocations ofprintf. The format string itself contains two%sformat specifiers. The first one includes a modifier,20-, which specifies a minimum width of twenty characters for the string.printf format, "Filename", "Permissions"These calls to
printf format, "--------", "-----------"printfare executed once in theBEGINblock to output column headings. They receive theformatvariable in addition to two regular strings for its items.printf format, $NF, $1Thisprintfis invoked for each input record the program receives. We provide it theformatvariable so the column data lines up with the headings appropriately. We also specify$NFand$1for the items which refer to the filename and permission strings in the input record.printf "\n\tFile count: %i\n", countWe call one moreprintfin theENDblock and pass it acountvariable, which stores the total number of records the program output. The%iformat specifier renderscountas an integer.
Notice that printf doesn't append a newline character to the end of its output; it is therefore necessary to provide one explicitly.
In additional to %s and %i, many more format specifiers are available to use with printf. A format specifier always starts with the percent character (%) and ends with a format-control letter - the most useful of which are listed here:
Modifiers are also specified in between a format specifier’s % character and format-control letter. They can be used for things like controlling number precision, padding and widths. Modifiers are completely optional, but I’ll provide a list of some portable ones here for completeness:
Built-In Functions
The AWK programming language provides many built-in functions that can be called in your programs. Built-in functions fall into three categories: numeric, string, and I/O. For example, the samples/filemod.awk program uses the following functions:
Of particular interest here is the system(command) function, which enables us to pass a string representing a shell command that is subsequently executed. The filemod.awk program utilizes this function to invoke a mv command in order to rename files:
command = sprintf("mv %s %s\n", filename, target)
system(command)The sprintf function firstly constructs and returns the command string before it is passed to system(). As you can imagine, the ability to dynamically construct arbitrary commands and execute them within a program is a powerful feature.
It is important to not leave a space between the function name and its parenthesis, as doing this could confuse the AWK interpreter depending on where the function is being called. I encourage you to check out the AWK programming manual to discover the many functions available to use in your programs.
In Conclusion
I hope that the content presented in this article has sparked an interest in the AWK programming language. With the fundamental concepts of how AWK works under your belt, I’m sure it will become a useful utility in your Linux toolbox for analyzing and filtering data on your system.
Keep an eye out for more AWK related articles coming from myself in the future. I also recommend a couple of resources to continue your learning:
- The GNU Awk User’s Guide: A thorough overview of Gawk and the AWK programming language.
- awklang.org: Τhe site for things related to the awk language
